证明零知识性¶
来源:
密码学引论 / zero_knowledge_proof/证明零知识性.md
证明零知识性¶
这里有两个东西:
表示一个随机变量/分布,通常理解成真实协议执行中验证者看到的东西。
表示另一个随机变量/分布,通常理解成模拟器伪造出来的东西。
零知识证明的目标就是说明:
也就是说,真实交互产生的内容,和模拟器不靠秘密信息生成的内容,在外人看来分不出来。
第一页说的是三种“不可区分”。
1. 相等¶
意思是: 对于任意输出 \(a\),两个分布输出它的概率完全一样。
这叫完美不可区分。
比如:
那么它们输出 0 和 1 的概率都一样,完全相等。
2. 统计不可区分¶
意思是: 两个分布可以不完全一样,但是整体差距非常小,小到可以忽略。
这里的
叫可忽略函数,意思是随着安全参数 \(\lambda\) 增大,它比任何多项式倒数都小,例如:
就可以认为是可忽略的。
所以统计不可区分就是:
哪怕给你无限算力,你也几乎分不出来。
3. 计算不可区分¶
其中:
意思是: 对于任何多项式时间算法 \(D\),它都无法有效地区分 \(U_\lambda\) 和 \(V_\lambda\)。
这里的 \(D\) 叫区分器。
你可以把它理解成一个裁判:
它拿到一个样本,然后判断:
“这个样本是来自真实协议 \(U_\lambda\),还是来自模拟器 \(V_\lambda\)?”
如果任何高效算法都猜不准,那就说明它们计算不可区分。
这三者强度关系是:
也就是:
完全一样最强; 统计距离很小次之; 只要求高效算法分不出来最弱。
放回“零知识性”里,这页想表达的是:
如果真实协议视图 \(U_\lambda\) 和模拟器生成的视图 \(V_\lambda\) 不可区分,那么验证者从真实交互中看到的东西,就完全可以由模拟器自己造出来。
既然模拟器不掌握秘密信息,却能造出几乎一样的东西,那说明真实协议也没有泄露秘密信息。
所以零知识性的本质就是:
验证者看不出来真假,因此它没学到额外知识。
成员的零知识证明¶
子群成员问题¶
schnorr协议

如果攻击者可以事先知道i的值,那直接可以伪造h
并行的协议无法证明零知识性
知识的零知识证明¶
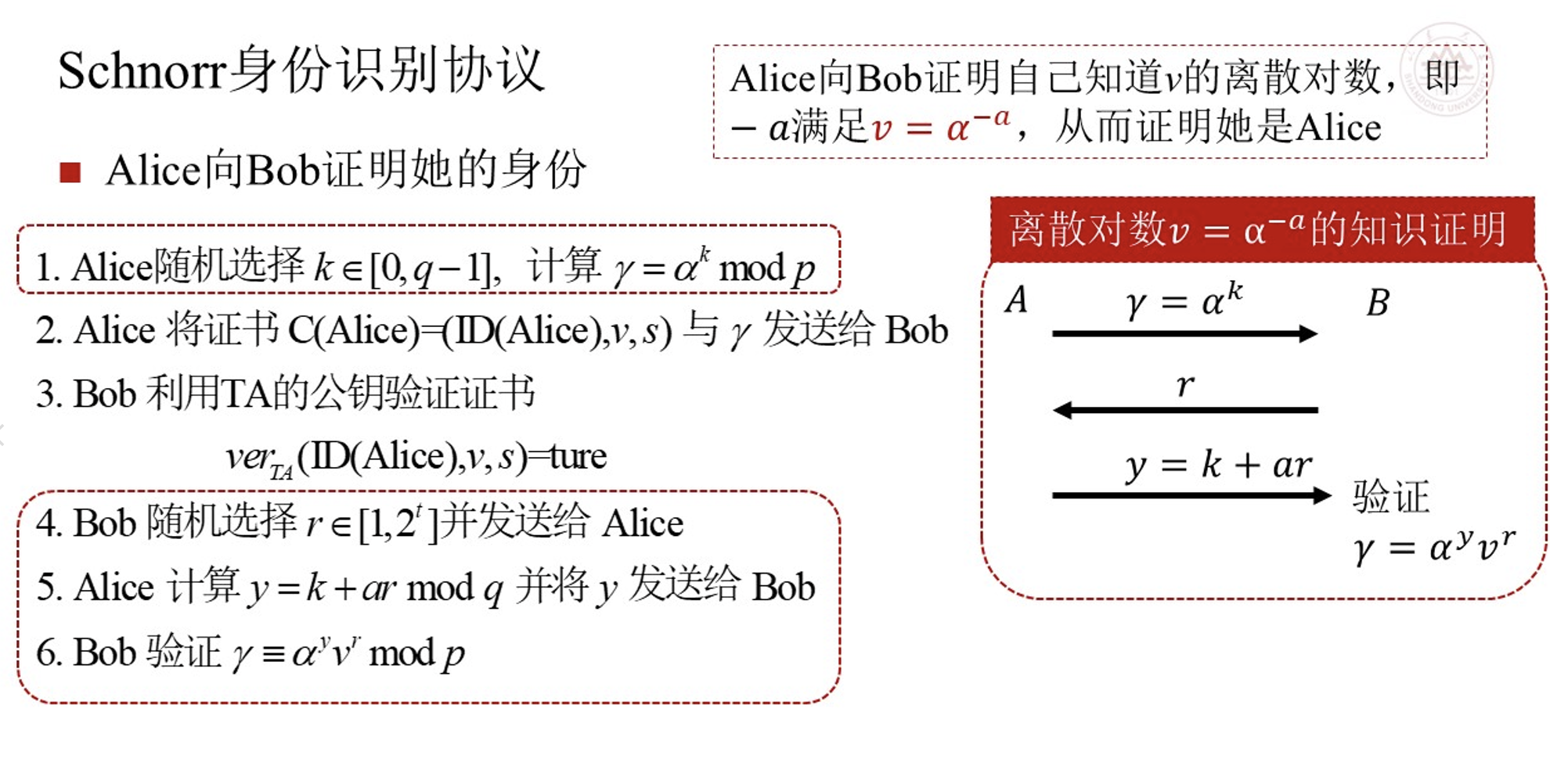
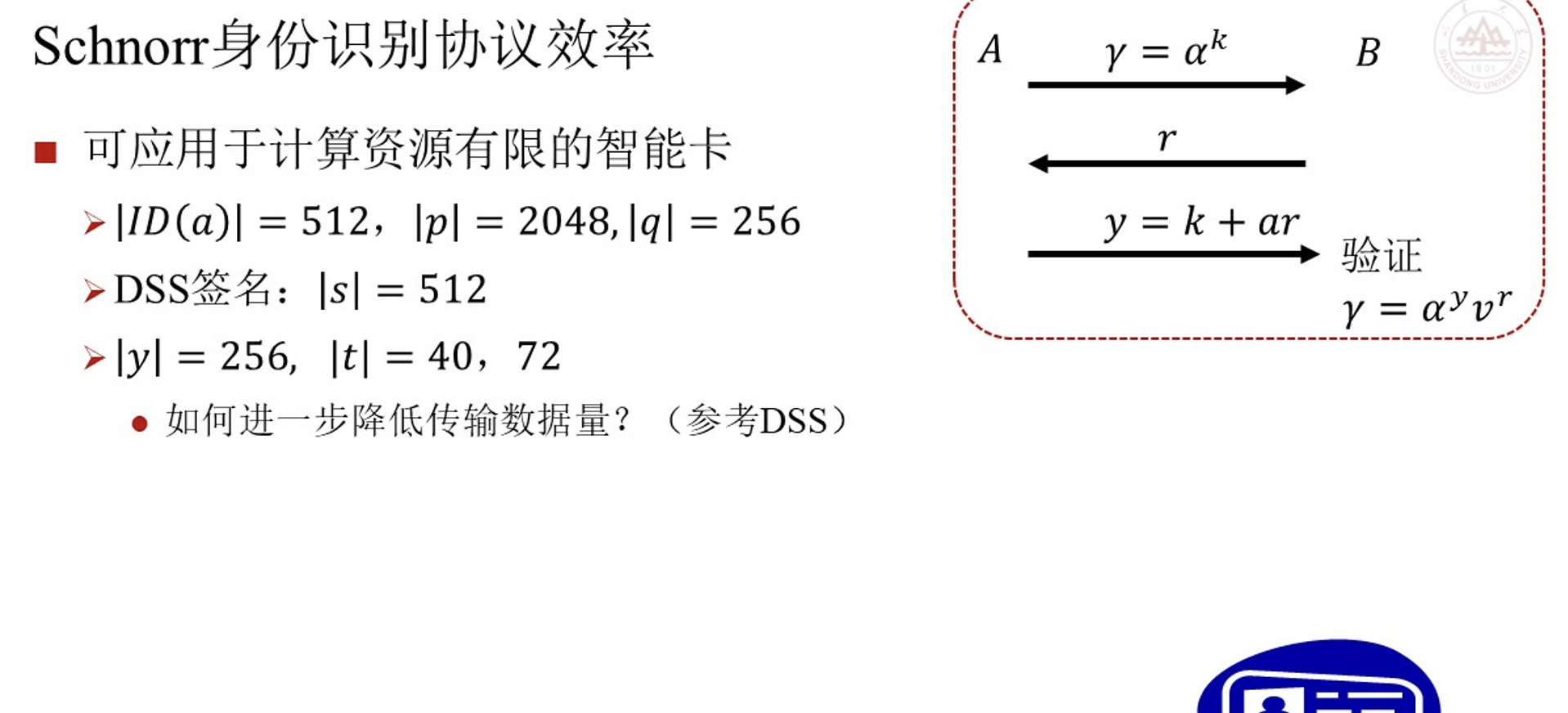
Schnorr身份识别协议¶
可以用于计算资源有限的智能卡
Fier-Shamit变换